
Generate realistic data.
Export to any format.
152 field types, statistical distributions, conditional weight overrides, and exports to CSV, SQL (7 dialects), JSON, JSONL, and Parquet.
152 Realistic Field Types
Domain-specific data generators across 19 categories
Basic & primitives
Integer, float, string, text, boolean, UUID, enum, date, datetime, integer sequence
Personal
Names, age, date of birth, gender, nationality, SSN, blood type, prefix, suffix, occupation
Contact
Email, phone number, area code, username, password
Address
Street, city, state, postal code, country, building number, secondary address, full address
Geographic
Latitude, longitude, license plate
Date & time
Future date, past date, time
Business & company
Company name, department, industry, sector, sub-industry, job title, catch phrase, vehicle
Commerce & products
Order ID, product name, product category, subcategory, type
Financial
Credit card, IBAN, SWIFT, currency code/amount, decimal, EAN, stock ticker, price, percentage, tax rate, discount
Internet & web
URL, domain name, image URL, emoji, hashtag, slug
Networking & developer
IPv4, IPv6, MAC address, port, HTTP method, MIME type, file extension, user agent, API key, locale, language code
Text & content
Word, sentence, paragraph, book title, ISBN-13
Healthcare
CPT code & description, NDC code/drug name/generic name, ICD-10 code & description
Hardware
CPU, GPU
Food & drink
Dish, drink
Education
Academic degree, university
Color
Color name, hex color
Measurement
Height, weight
Fantasy & creative
Character class, item, name, race, spell, weapon
Constraints & Correlations
Fine-grained control so your generated data looks and behaves like the real thing
Value Ranges
Set minimum and maximum values for numeric fields. Define valid ranges for prices, ages, quantities.
String Length
Control minimum and maximum length for text fields. Perfect for usernames, descriptions, IDs.
Regex Patterns
Generate data matching specific patterns. Ideal for custom IDs, codes, formatted strings.
Enumerated Values
Restrict fields to specific allowed values. Great for status fields, categories, types.
Weighted Distribution
Control percentage distribution across values, or apply statistical distributions like Normal, LogNormal, Exponential, and Triangular to numeric fields.
Date Ranges
Constrain dates to specific periods. Set start and end for timestamps and date fields.
Field Correlations
Fields that make sense together - cities match their states, product prices vary by category, birth dates match age ranges, and order totals match line item sums. Correlations catch bugs that only surface with realistic value combinations.
Statistical Distributions
Generate statistically realistic data instead of flat random values
Probability Distributions
Model real-world data patterns
Apply Normal, LogNormal, Exponential, or Triangular distributions to any numeric field. Generate salary data that clusters around a median, response times with a long tail, or test scores that follow a bell curve.
Conditional Overrides
Distributions that vary by context
Change how a field is distributed based on another field's value. Salary distributions that shift by department, price ranges that vary by product category, or age distributions that differ by region. Your test data reflects the same patterns as production.
Intelligent Data Generation
Fields that understand each other - dependencies and derived rules produce data that makes sense together
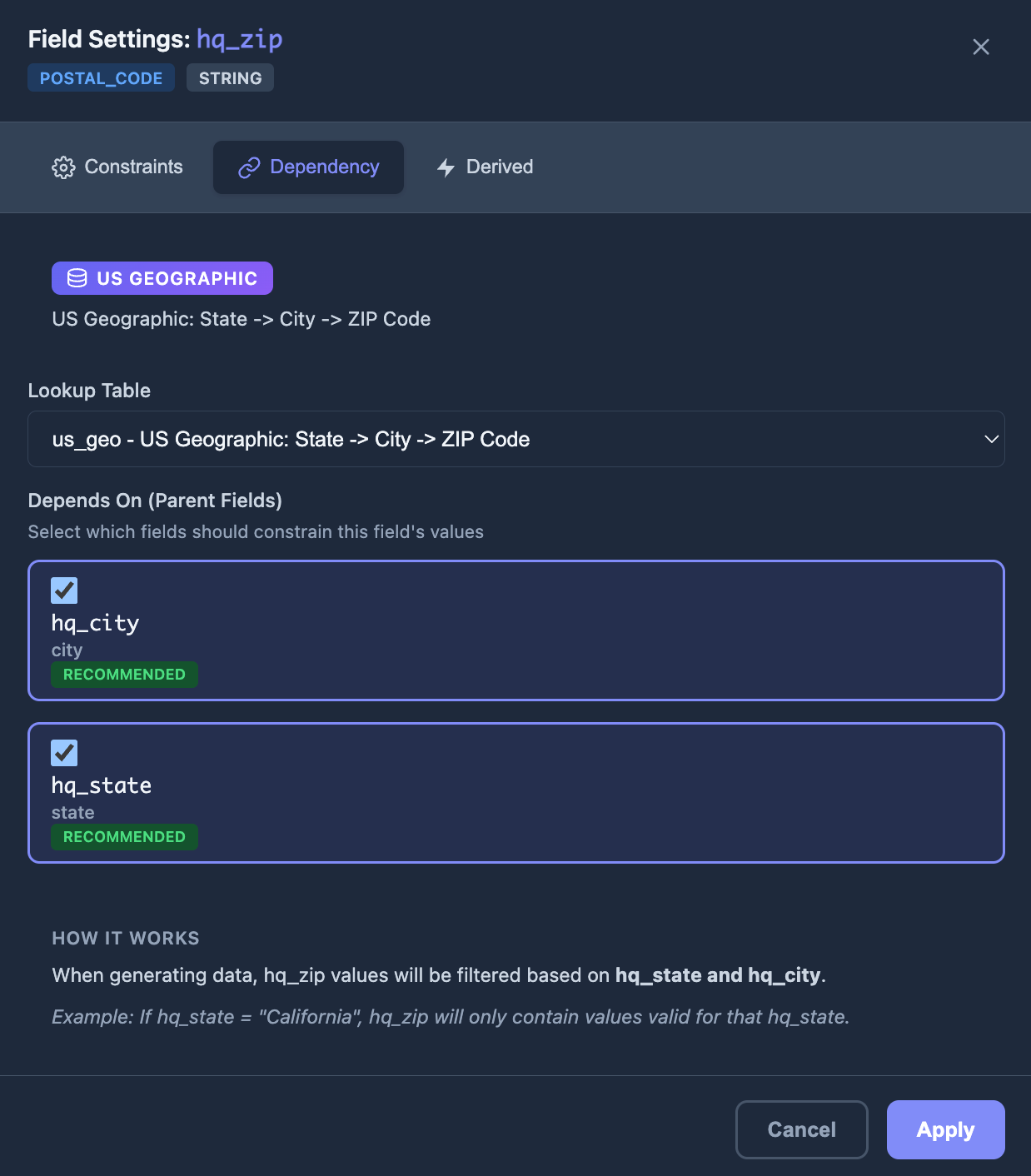
Field Dependencies
Lookup tables keep related values consistent
AI-generated schemas with state, city, and ZIP columns get coherent geographic dependencies wired automatically - no clicks required. Same for sector/industry/sub-industry chains. ZIP codes always match their city and state by construction; industry codes always roll up to a real sector. Hand-edit the dependencies in the visual editor when you want different parent fields.
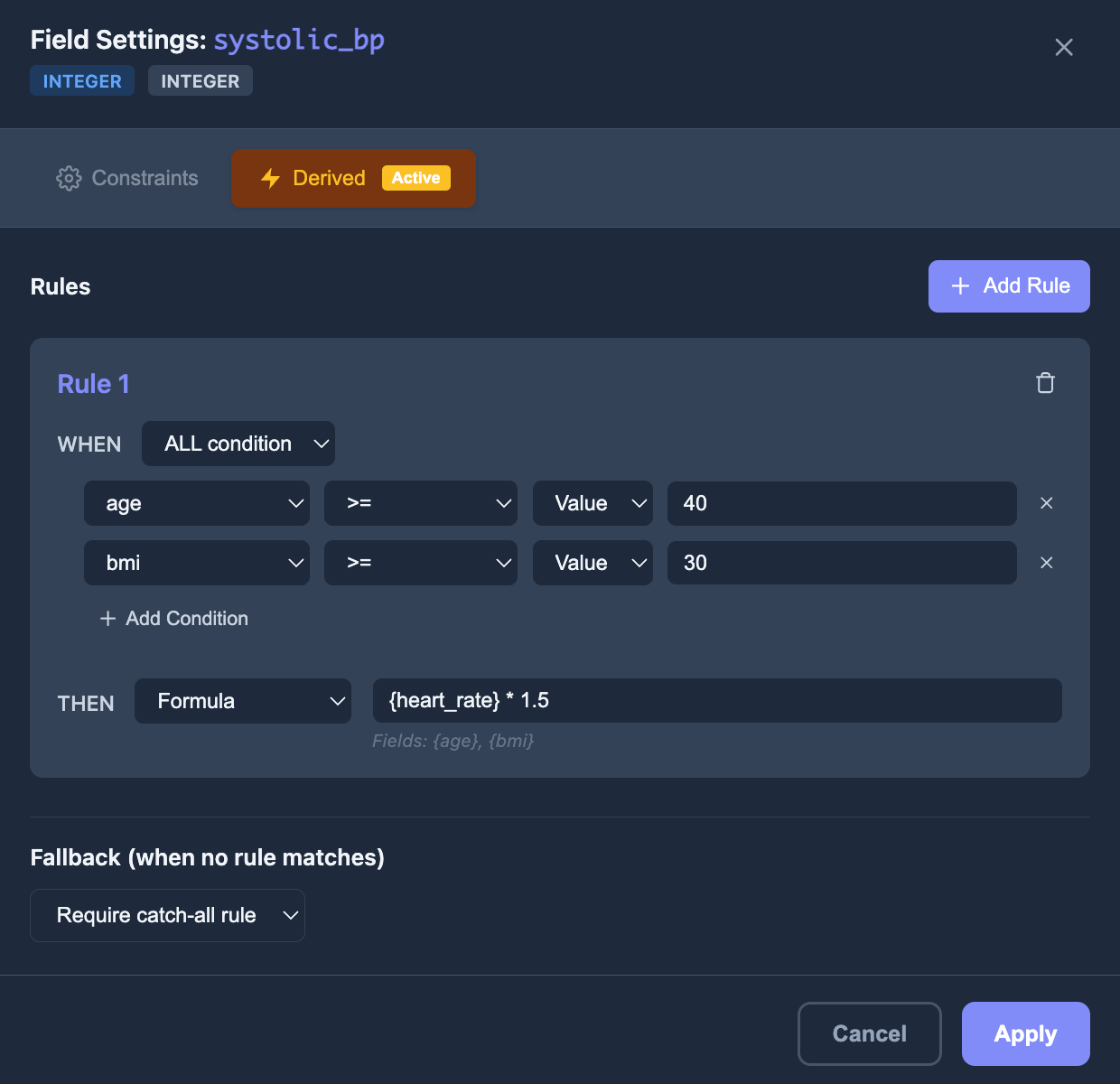
Derived Rules
Conditional logic that mirrors real-world relationships
Define WHEN/THEN rules with formulas that reference other fields. Example: when age >= 40 and BMI >= 30, multiply heart rate by 1.5. Build realistic correlations that simple random generation can't produce.
Cardinality Ratios
Per-relationship row count math, so child tables scale with their parents
Per-Relationship Ratios
Children scale with parents, not by hand
Set "8-12 patients per doctor" or "100-500 line items per order" instead of hand-typing a row count for every child table. SynthForge picks a uniform-random multiplier per parent and resolves child counts in topological order. Multiple parent ratios on the same child (M:N junction tables) sum naturally.
Auto-Saved Defaults
Last generation's settings come back next time
Every successful generation persists its row counts and ratios as the schema's defaults. Open the same schema's generation form tomorrow, next month, or from a different machine - the inputs come back exactly the way you left them. No more re-typing 100, 100, 100 across every table.
The Most Flexible Export Options Available
No other synthetic data generator supports this many database types, export formats, and configuration options, all included for free.
CSV
SQL
JSON
MongoDB
Parquet
SQLite
Relational Databases
7 SQL dialects with dialect-specific DDL and bulk loading
COPY command, serial/identity columns, array types
LOAD DATA INFILE, auto_increment, engine options
BULK INSERT, identity columns, T-SQL syntax
.import command, lightweight DDL, binary file export
MySQL-compatible with MariaDB-specific optimizations
COPY FROM, columnar analytics-optimized DDL
IMPORT INTO, distributed-compatible DDL
Every dialect includes CREATE TABLE, bulk loading commands, and FK constraints optimized for the target database.
Document, Analytics & Files
MongoDB, JSON variants, Parquet, CSV, and SQLite binary
MongoDB
Embedded documents from related tables, mongoimport-ready output
JSON - 6 structures
Parquet - 4 compression algorithms
CSV & SQLite Binary
Standard CSV export and downloadable SQLite database files ready to query
Generate Data. Visualize It Your Way.
Take SynthForge IO data and plug it into your favorite tools - these charts were built from our Ecommerce and Banking template schemas using Matplotlib
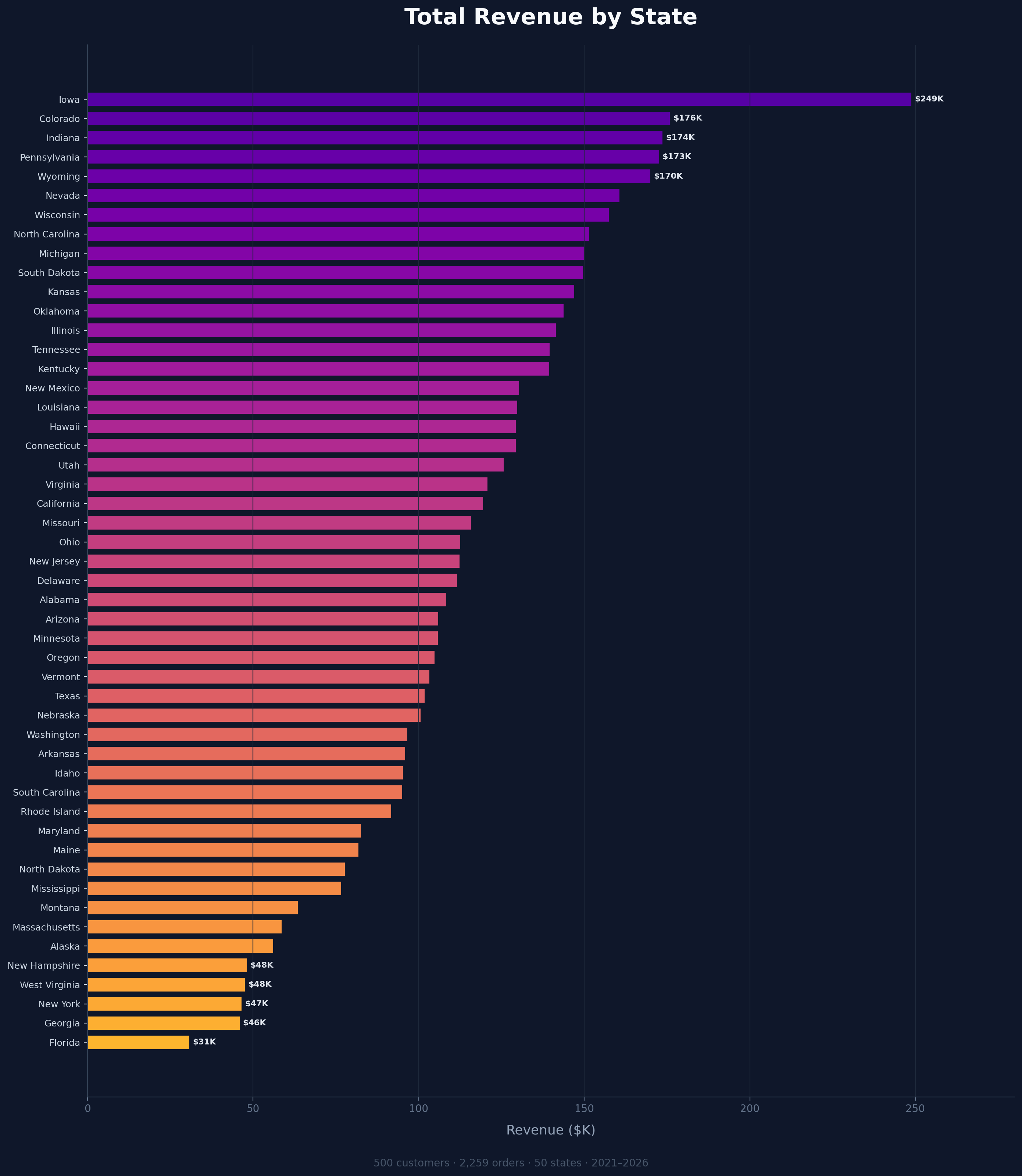
Total Revenue by State
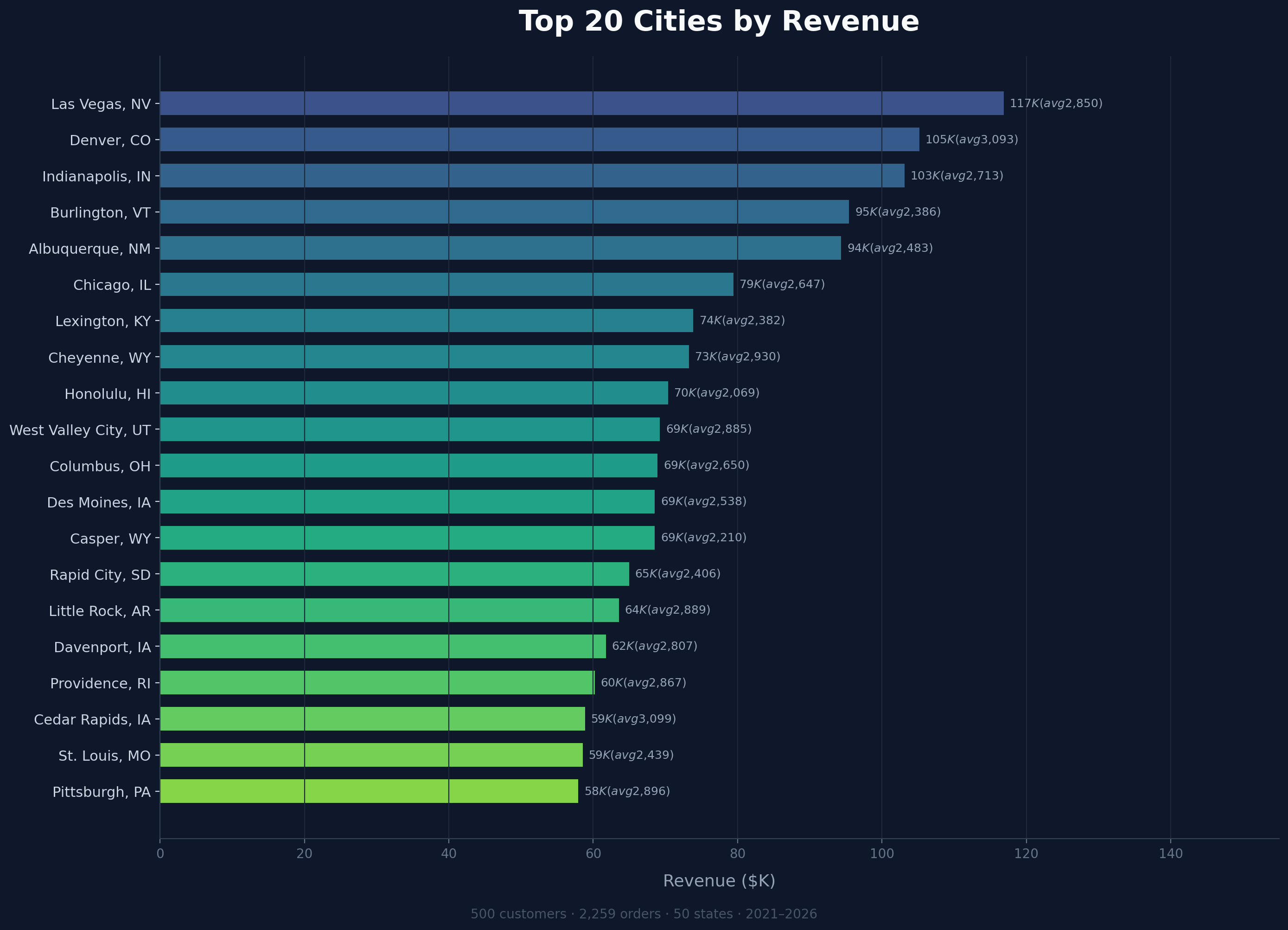
Top 20 Cities by Revenue
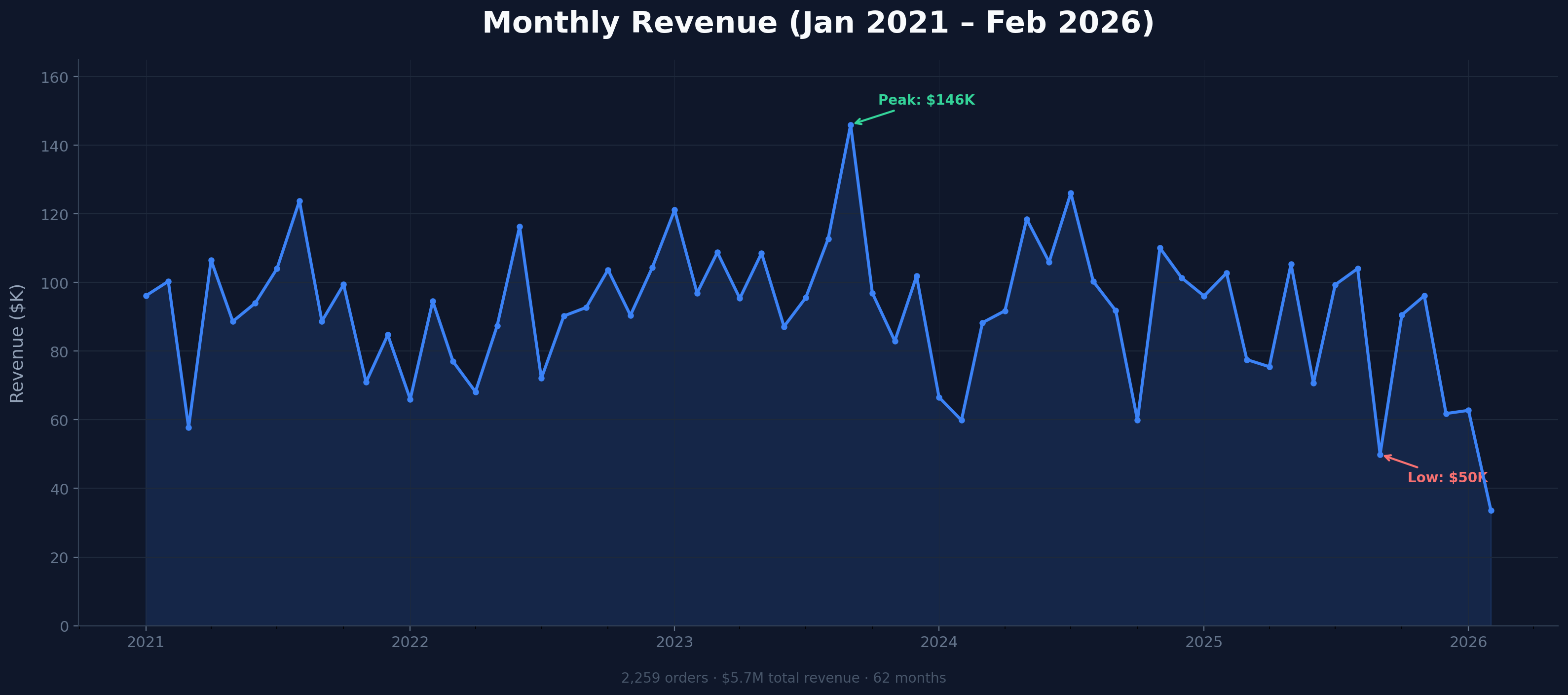
Monthly Revenue Trend (2021-2026)
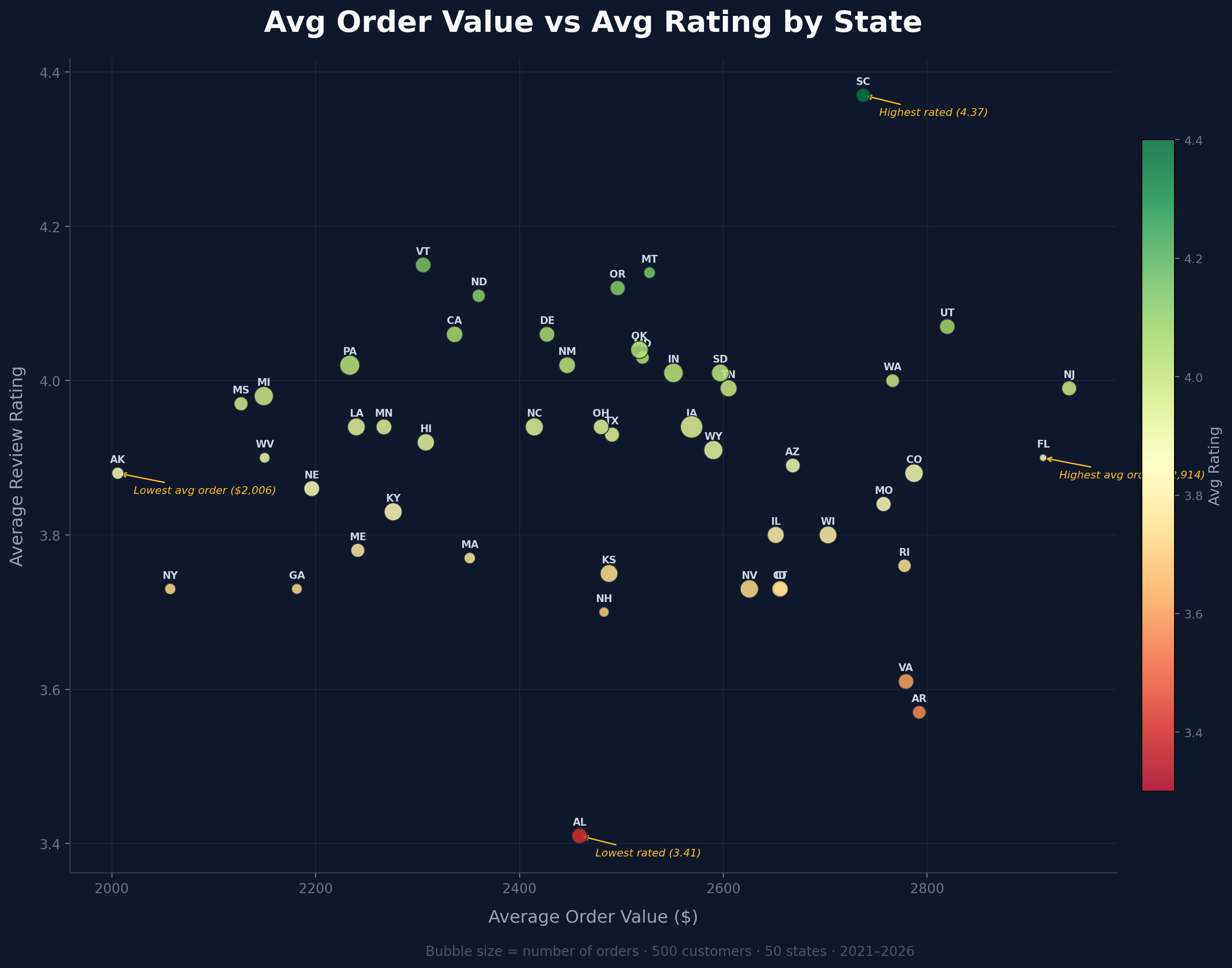
Avg Order Value vs Avg Rating by State
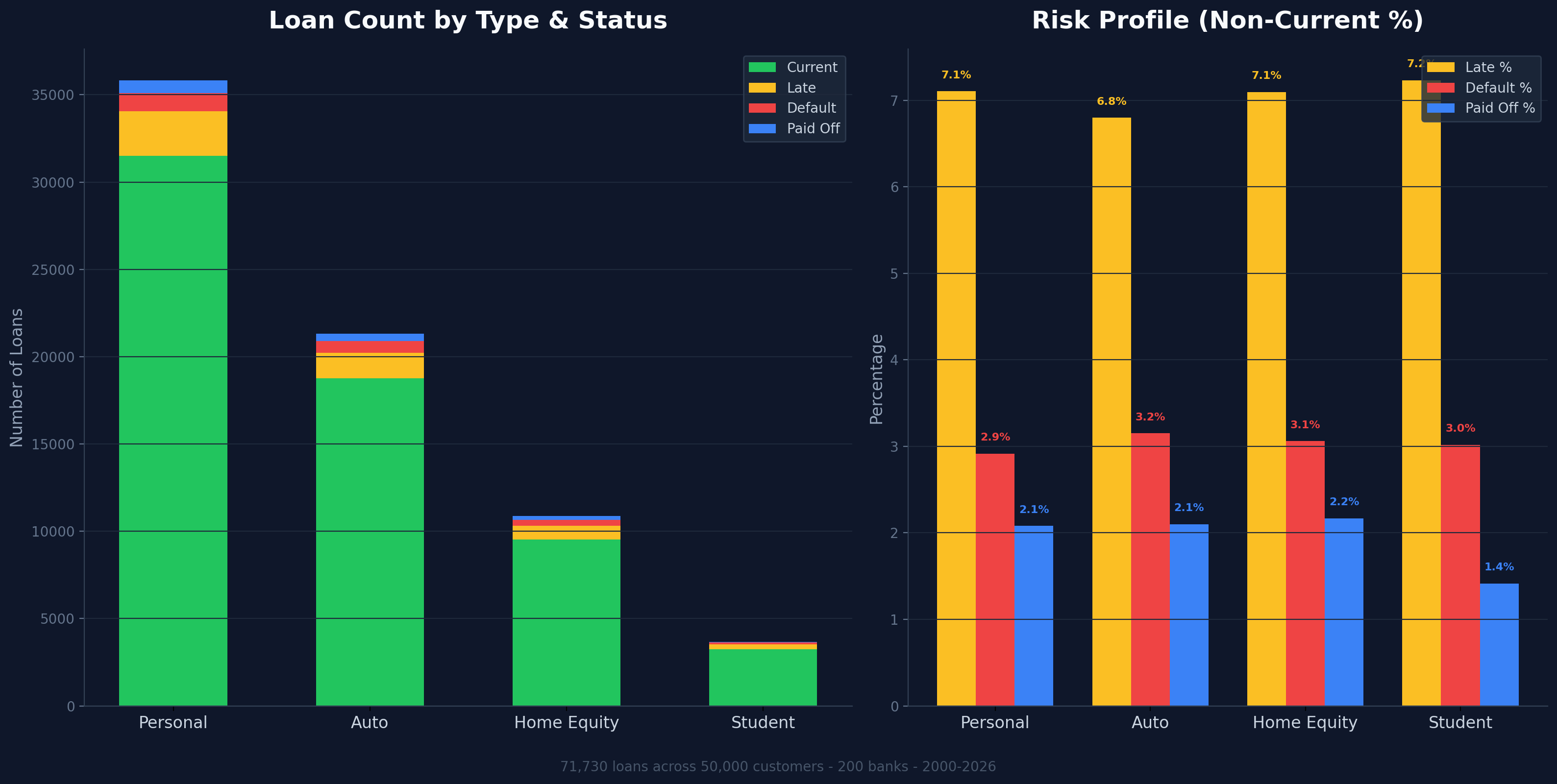
Loan Risk Profile by Type
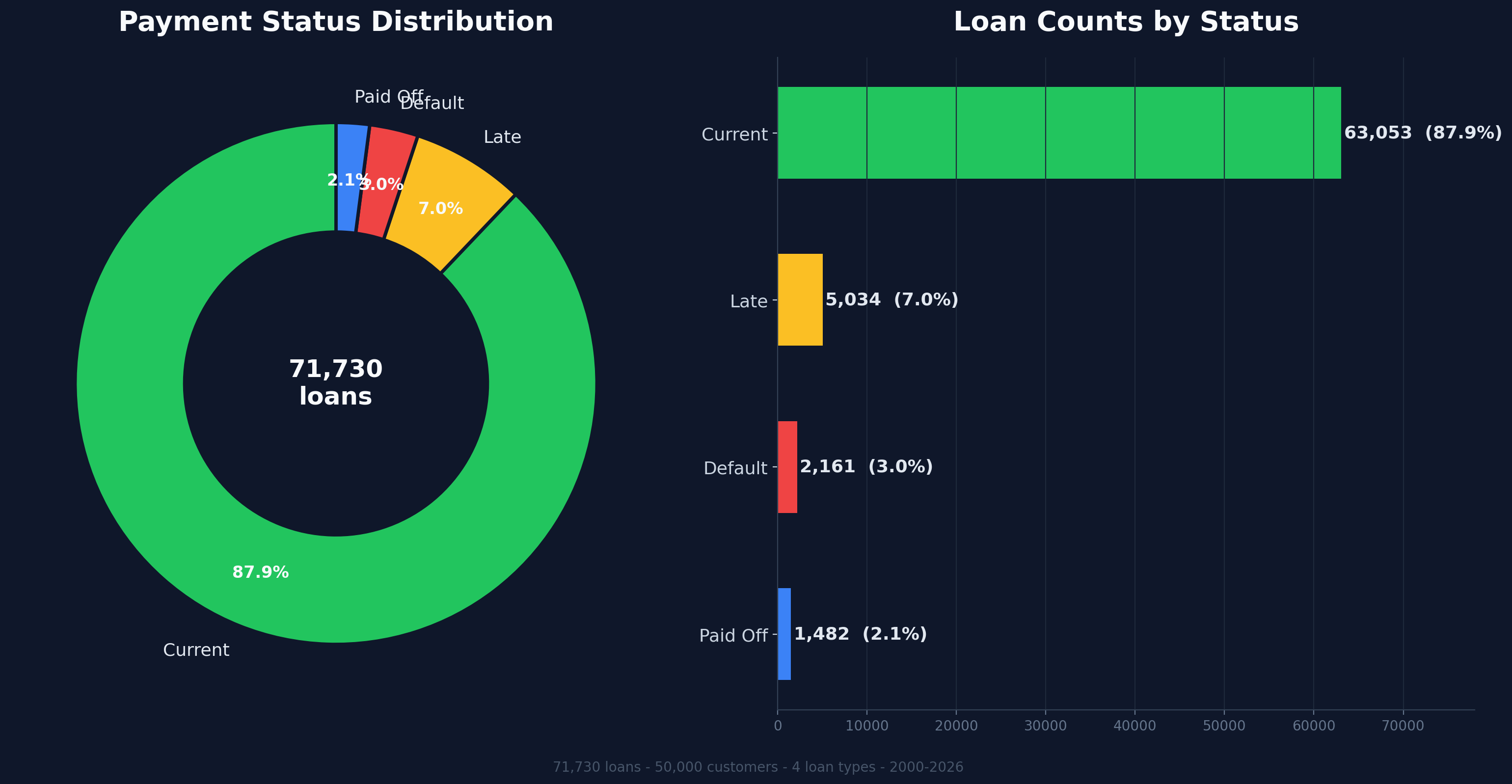
Loan Payment Status Distribution
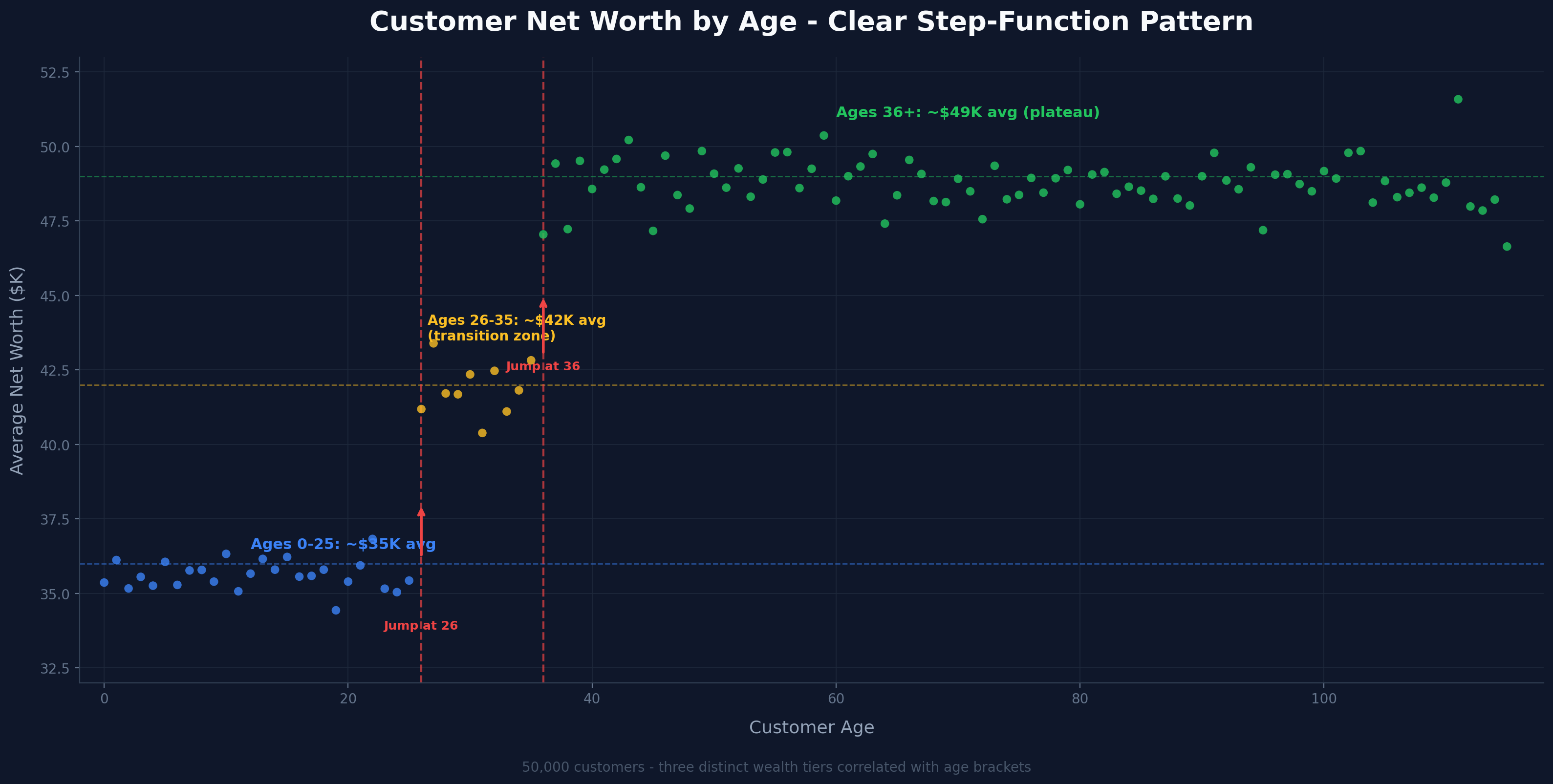
Customer Net Worth by Age - Step-Function Correlation
Data generated by SynthForge IO - charts rendered with Matplotlib
Built for Scale
Real-Time Progress
Live progress tracking that reports actual rows completed per entity, not a fake progress bar. See exactly where your generation stands with per-table breakdowns updated every second.
Million-Row Datasets
Generate production-scale datasets with full referential integrity. Automatic dependency ordering and chunk-based processing keep memory usage constant regardless of dataset size.
Built for Developers
Real scenarios, real solutions
Application Developer
"Test your API with realistic payloads"
Generate request/response data that matches your schema. Catch edge cases before they reach production. Fill your dev database with realistic records.
QA Engineer
"Edge cases don't hide from realistic data"
Generate thousands of test records with diverse, realistic values. Cover boundary conditions automatically. Test with production-scale volumes.
Data Engineer
"Prototype pipelines with production-scale data"
Test ETL pipelines before production data exists. Validate transformations with realistic datasets. Generate millions of rows for load testing.
Frequently Asked Questions
What field types does SynthForge IO support?
SynthForge IO ships 152 field types across 19 categories: Basic (integer, float, boolean, date, datetime, uuid, string, text, enum, integer sequence), Personal (first name, last name, full name, email, phone number, ssn, license number, age, area code, blood type, date of birth, gender, nationality, occupation, password, prefix, suffix, username), Address (street address, city, state, postal code, country, street name, street suffix), Geographic (building number, full address, latitude, license plate, longitude, secondary address, country code, state abbr), Internet (url, ipv4 address, domain name, ipv6 address, http status code, tld), Commerce (credit card number), Financial (bank name, bank routing number, currency code, decimal, ean, iban, stock ticker, swift code, currency amount, discount amount, price, percentage, tax rate, credit card provider, bitcoin address, credit card expiration date, cvv, ethereum address), Medical (cpt code, cpt description, ndc code, ndc drug name, ndc generic name, icd10 code, icd10 description, hcpcs code, hcpcs name, icd9 diagnosis code, icd9 dx desc short, icd9 dx desc long, icd9 procedure code, icd9 proc desc short, icd9 proc desc long, hospital name, hospital npi), Business (catch phrase, company name, department, industry, job title, order id, product name, vehicle, sector, sub industry, product category, product subcategory, product type, ein, buzzword, slogan), Temporal (future date, past date, time, timezone), Technical (api key, emoji, file extension, hashtag, http method, image url, language code, locale, mac address, mime type, port, slug, user agent, md5, sha1, sha256, file name, programming language, os, mongodb objectid, ulid), Text (book title, paragraph, sentence, word, isbn13, isbn10), Fantasy (fantasy class, fantasy item, fantasy name, fantasy race, fantasy spell, fantasy weapon), Hardware (cpu, gpu), Food (dish, drink), Measurement (height, weight), Education (academic degree, university), Color (color name, hex color), Automotive (vin, car model year, car make, car model).
What export formats are available?
SynthForge IO exports to CSV, SQL (DDL + native bulk-load scripts for PostgreSQL, MySQL, SQLite, SQL Server, MariaDB, DuckDB, and CockroachDB), JSON, JSONL, and Apache Parquet. JSON / JSONL output is MongoDB-ready - load it via mongoimport. Each SQL export includes CREATE TABLE statements, bulk loading commands (\copy, LOAD DATA INFILE, bcp, etc.), and FK constraints optimized for the target database.
How do constraints and correlations work?
You can set value ranges, string length limits, regex patterns, enumerated values, distribution ratios, and date ranges on any field. Field dependencies use lookup tables to keep related values consistent (e.g., ZIP codes match their city and state). Derived rules let you define WHEN/THEN conditional logic with formulas that reference other fields.
What are statistical distributions and conditional overrides?
Statistical distributions let you apply Normal, LogNormal, Exponential, Triangular, or Uniform probability distributions to numeric fields - so salary data clusters around a median, response times have a realistic long tail, or test scores follow a bell curve. Conditional weight overrides take this further: you can vary sampling weights based on another field's value (e.g., shift category weights by department, or product-tier weights by region).
Can I set per-relationship row count ratios (e.g. N children per parent)?
Yes. For any child table that has a foreign key to a parent, the generation form lets you toggle from a fixed row count to a 'per parent row' ratio. Specify a min - max range (e.g. '8 to 12 patients per doctor') and SynthForge picks a uniform-random multiplier per parent. Ratios resolve in topological FK order, so a chain like doctors -> patients -> visits cascades automatically. Multi-parent ratios on the same junction table sum together (so '20 appointments per doctor' + '5 appointments per patient' produces a junction that respects both axes). Top-level tables stay as plain row counts.
Does SynthForge remember my last generation settings?
Yes. Every successful dataset job persists its row counts and any ratios as the schema's defaults. The next time you open the generation form for that schema, the inputs pre-fill with what you last submitted. Override anything before regenerating; the new values overwrite the defaults. Works across browsers and devices since the defaults live on the schema record, not in local storage.
Start Generating Realistic Data
152 field types, fine-grained constraints, and export to any format your stack needs.