
Generate ML training datasets.
Build better models.
Full control over features, distributions, class balance, and data quality. Export publication-ready datasets with stratified train/test splits and a baseline model evaluation. No licensing issues, no hidden costs.
Why build your own training data?
Proprietary datasets are expensive, poorly documented, and often disappointing. Build exactly what you need instead.
Hidden costs add up
Dataset quality is the biggest hidden cost in ML projects. Data that looks good on paper can perform terribly in practice. With SynthForge IO, what you configure is what you get.
Quality is opaque
Bought datasets often lack annotation transparency, inter-annotator agreement scores, or benchmark results. If a vendor can't explain their process, it's a red flag.
Differentiation matters
If everyone trains on the same open datasets, everyone builds the same models. There is more to be gained in data than in using different architectures.
Full Control Over Every Feature
Define features with precise types, distributions, and constraints
Numeric Features
Configure mean, standard deviation, and min/max bounds. Choose from 9 statistical distributions to match your domain.
Categorical Features
Define categories with custom weights for realistic distribution. Control how frequently each category appears in your dataset.
Boolean Features
Binary true/false features with configurable probability. Set the true ratio to match your domain requirements.
Predictive Strength
Control how strongly each feature correlates with the target label. High predictive strength means the feature is a strong signal; low strength means it's mostly noise. This lets you test how well your model identifies useful features.
Noise Control
Add controlled noise to your data to test model robustness. Adjust the noise level from perfectly clean to heavily noisy. Real-world data is never clean - simulate it before your model encounters it in production.
Class Balance Under Your Control
Configure target labels with custom weights to simulate real-world class distributions
Label Configuration
-
Custom class labels
Define as many target classes as you need with descriptive names.
-
Weighted class distribution
Set exact weights per class. Simulate 95/5 imbalance for fraud detection, 70/20/10 splits for multi-class problems, or perfectly balanced datasets.
-
100% label consistency
Labels are generated deterministically. No inter-annotator disagreement - unless you intentionally enable label noise.
Common Patterns
Binary Classification
Spam/Not Spam, Fraud/Legitimate, Churn/Retain - with configurable imbalance ratios
Multi-Class Classification
Sentiment analysis, product categories, disease diagnosis - any number of classes with weighted distributions
Regression
Continuous target variables for price prediction, revenue forecasting, and other regression tasks, with R-squared, RMSE, and MAE evaluation
Imbalanced Datasets
Test how your model handles rare events. Set minority class to 1-5% to simulate real-world anomaly detection scenarios
Realistic Data Imperfections
Real-world data is never clean. Simulate production conditions before your model encounters them.
Missing Values
Inject NaN values at a configurable rate per feature. Test your imputation strategies and see how missing data affects model performance.
Label Noise
Intentionally mislabel a percentage of samples to simulate annotation errors. Test how robust your model is to noisy ground truth.
Duplicate Rows
Inject duplicate records at a set rate. Validate that your preprocessing pipeline handles deduplication correctly.
Outliers
Inject extreme values at a configurable rate. Test whether your model is resilient to outliers or gets distorted by them.
Train / Test / Validation Splits
Four splitting strategies for different ML workflows. Configure ratios and get separate files per split.
Random
Shuffled random split. Simple and effective for most datasets.
Stratified
Preserves class distribution across all splits. Essential for imbalanced datasets.
Temporal
Time-based ordering for time-series data. Train on the past, test on the future.
Group
Keeps related records together. Prevents data leakage across patient IDs, user sessions, etc.
Configure the train/test ratio (e.g., 80/20, 70/30). Train and test partitions are exported as separate files in the ZIP download, ready for immediate use with scikit-learn, PyTorch, TensorFlow, or any ML framework. A 3-way validation split is on the roadmap; for now, partition the train set further with your framework's split helper.
Feature Correlations
Real-world features are rarely independent. Height correlates with weight. Income correlates with education level. Age correlates with years of experience.
SynthForge IO lets you define a correlation matrix between features, producing multi-feature datasets that reflect real-world inter-feature dependencies. This bridges the gap between abstract statistical generation and domain-realistic data.
Define pairwise correlation coefficients between numeric features
Positive and negative correlations supported
Verified in the data quality report
// Example correlation matrix
correlations: {
height <-> weight: +0.85
age <-> experience: +0.72
price <-> demand: -0.65
income <-> education: +0.58
}
Domain-Aware Templates
Start with pre-configured feature sets for common ML domains. Customize everything after.
Healthcare
Patient demographics, vital signs, lab values, diagnosis codes. Pre-configured distributions matching clinical data patterns.
View Healthcare template ->
E-commerce
Purchase history, session data, product categories, user behavior. Realistic distributions for conversion prediction and recommendation systems.
View E-commerce template ->
IoT / Sensor Data
Temperature readings, vibration sensors, pressure gauges, equipment status. Time-series patterns for predictive maintenance and anomaly detection.
View Sensor template ->
Financial / Fraud
Transaction amounts, account balances, credit scores, risk indicators. Log-normal distributions for monetary values, configurable fraud rates.
View Fraud template ->
HR / People Analytics
Employee demographics, performance metrics, tenure, satisfaction scores. Correlated features for attrition prediction and workforce planning.
Marketing
Campaign metrics, customer segments, engagement scores, conversion funnels. Build churn prediction and customer lifetime value models.
View Marketing template ->
Housing Price
Square footage, bedrooms, lot size, property type. Correlated features with continuous price targets for regression modeling.
View Housing template ->
Know What You Generated
Every export includes a quality report. Optionally run a baseline model to verify the data is useful.
Data Quality Report
Included in every ZIP export. Immediate visibility into what you generated.
-
Distribution statistics per feature
-
Class balance breakdown
-
Feature correlation matrix
-
Predictive strength verification
-
Summary statistics and missing value counts
Baseline Model Evaluation
Answers the fundamental question: is this data actually useful for ML?
-
Trains logistic regression or decision tree on your data
-
Reports accuracy, precision, recall, and AUC
-
Feature importance ranking
-
Validates data before investing in complex architectures
-
Optional - enable per dataset
Preview Before You Generate
Tune with 100-row previews. Export the full dataset when you're satisfied.
100-Row Preview
Generate a small sample instantly. Inspect distributions, verify class balance, and check feature values before committing to a full dataset.
ZIP Export
Download a ZIP with separate CSV and Parquet files for train, test, and validation splits, plus an auto-generated Jupyter notebook for immediate exploration and modeling.
No Licensing Constraints
Generated data is yours. No attribution required, no usage limits, no compliance concerns. Use it for training, testing, publishing, or sharing.
See the Output
Four ready-to-use datasets covering classification, regression, feature correlations, and data imperfections, each with a Jupyter notebook for exploration and modeling.
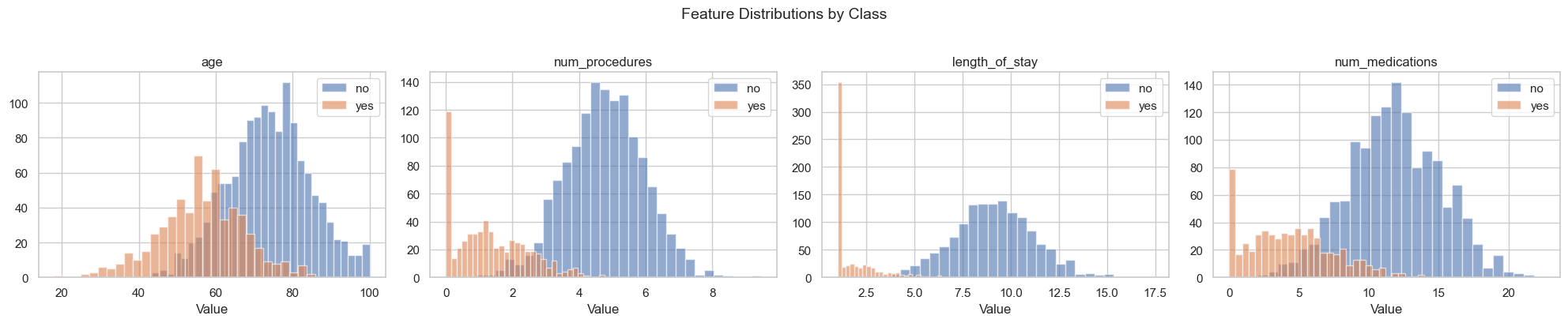
Feature Distributions by Class
Healthcare readmission dataset. Histograms for each numeric feature, split by target class
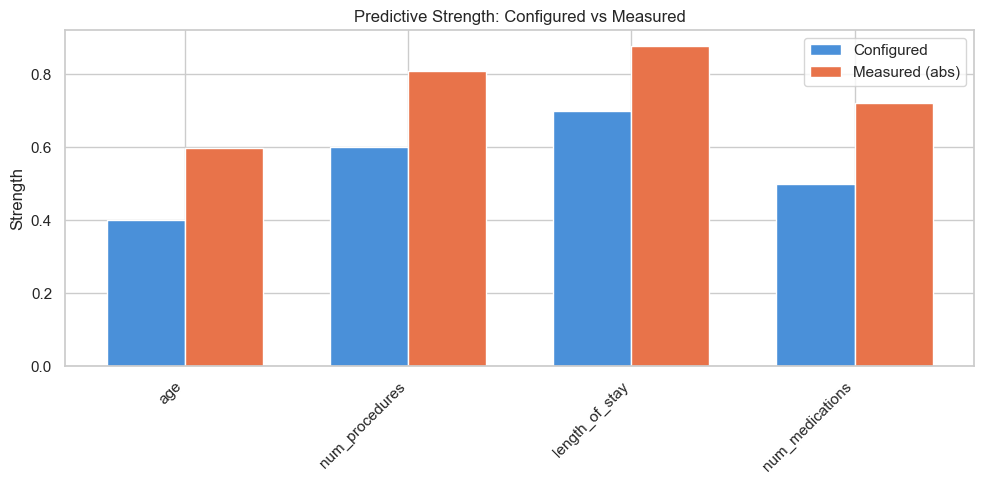
Predictive Strength: Configured vs Measured
Verify that each feature carries the signal strength you specified in the configuration
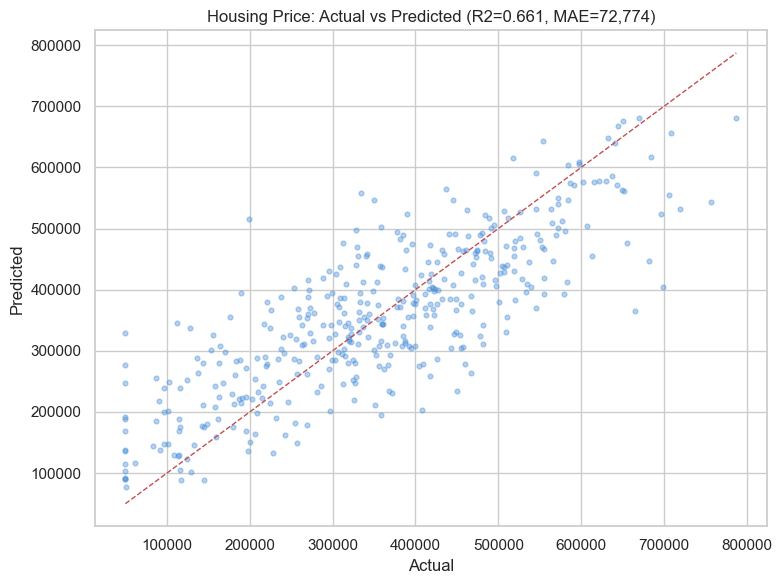
Actual vs Predicted (Regression)
Housing price dataset. Random Forest predictions plotted against actual values
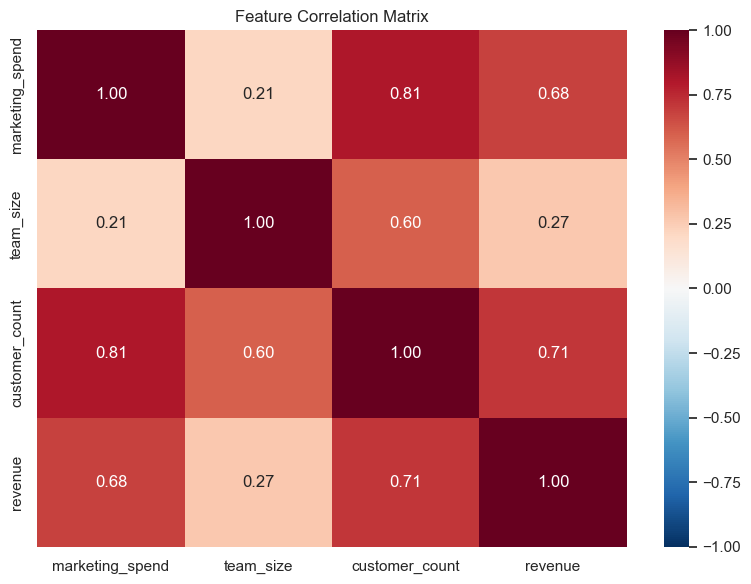
Feature Correlation Matrix
Correlated regression dataset. Configured inter-feature correlations verified in the output
The sample pack includes 4 datasets with train/test splits (CSV + Parquet), quality reports, baseline evaluations, and Jupyter notebooks:
Healthcare Readmission
Binary classification
Housing Price
Regression
Imperfect Binary
Data imperfections
Correlated Regression
Feature correlations
Built For
ML Engineers
Prototype models with controlled data. Test how architecture choices perform across different data characteristics - noise levels, class balance, feature correlations.
Researchers & Educators
Generate reproducible datasets for papers, coursework, and experiments. Control every variable so results are explainable and comparable.
Data Teams
Build training datasets without waiting for production data access. No privacy reviews, no compliance bottlenecks, no vendor negotiations.
Frequently Asked Questions
What types of ML datasets can SynthForge IO generate?
SynthForge IO generates supervised learning datasets for classification and regression tasks. You define features (numeric, categorical, boolean), configure their statistical distributions, set target labels with custom class weights (classification) or continuous value ranges (regression), and control how predictive each feature is. The result is a ready-to-train dataset with a stratified train/test split.
How does SynthForge IO ensure label consistency?
Labels are generated deterministically based on your configuration - predictive strength, noise level, and class weights. Because the data is generated to spec rather than manually annotated, label consistency is 100% by construction. There is no inter-annotator disagreement unless you explicitly enable label noise to test model robustness.
Can I simulate real-world data imperfections?
Yes. SynthForge IO lets you inject missing values (configurable rate per feature), label noise (intentional mislabeling at a set percentage), duplicate rows, and outliers. This produces datasets that behave like real-world data, letting you test how your models handle messy inputs before deploying to production.
What splitting strategies are available?
SynthForge IO splits each generated dataset into train and test partitions, stratified for classification problems (so class distribution is preserved on both sides) and randomly partitioned for regression. You configure the train ratio (defaults to 0.8) and get separate train and test files in the exported ZIP. A 3-way train/test/validation split is on the roadmap; for now, partition the train set further with sklearn.model_selection.train_test_split or your framework's equivalent.
How do feature correlations work?
By default, features are independent conditioned on the target. You can define a correlation matrix to introduce inter-feature dependencies - for example, making height correlate with weight, or income correlate with education level. This produces more realistic multi-feature datasets that reflect real-world relationships.
What is the data quality report?
Every exported ZIP includes a data quality report with distribution statistics per feature, class balance breakdown, feature correlation matrix, predictive strength verification, and summary statistics. This gives you immediate visibility into what you generated without needing to write analysis code.
How does baseline model evaluation work?
After generation, SynthForge IO trains a baseline on your dataset and reports its metrics. For classification: a majority-class predictor and a threshold classifier on the strongest numeric feature, with accuracy, precision, recall, and F1. For regression: a mean predictor and a simple linear fit, with R-squared. The baseline gives you a floor: any real model you train should beat it by a meaningful margin, or the data is not actually predictive.
Are there licensing restrictions on generated datasets?
No. Synthetic data generated by SynthForge IO has no licensing constraints. You own the output completely - use it for training, testing, benchmarking, publishing, or sharing with your team. No attribution required, no usage limits, no compliance concerns.
Start Generating ML Training Data
Full control over features, distributions, splits, and imperfections. Free to use, no licensing constraints.